
Training a Portrait DiT on a Single GPU: What the Ablation Study Taught Us
The prevailing assumption in generative AI is that training a large, multi-modal Diffusion Transformer from scratch requires a cluster. prx-tg is a direct challenge to that assumption: a 400M+ parameter DiT for 1024×1024 portrait generation, trained entirely on a single consumer NVIDIA RTX 4090 with 24GB of VRAM, conditioned on text, identity, spatial layout, and pose simultaneously. We just completed the first systematic ablation study of its core training innovations, and the results are worth sharing in detail — including one finding we did not expect.
- What We Are Building
- The Ablation Design
- Results
- The Traps Ahead
- What’s Next
- Code and Data
- References
What We Are Building
prx-tg is a portrait generation model built on a NanoDiT backbone (Peebles & Xie, 2023) operating directly in pixel space, patchifying RGB images into a sequence of tokens rather than relying on a VAE latent bottleneck. The model is “quad-conditioned”: cross-attention layers simultaneously receive dense text captions processed by CLIP and T5, visual identity embeddings from DINOv3 (utilizing patch-level tokens), spatial layout maps, and DWPose skeletal keypoints. The goal is controllable generation — given a reference identity and a description of pose, lighting, and appearance, generate a plausible, photorealistic portrait.
Training a model of this scope on 24GB of VRAM is not possible without careful engineering. Gradient checkpointing drops all intermediate activations and recomputes them on the backward pass, trading a 20–30% speed penalty for a massive memory reduction. The T5 encoder alone consumes over 10GB of VRAM to process captions; a dedicated cleanup routine migrates it to CPU immediately after embeddings are cached, freeing the GPU before the DiT backward pass. Affine biases are stripped from QKV projections and FFN hidden layers — mathematically redundant under LayerNorm, and worth 5–10% of total memory. Positional embeddings are computed dynamically from latent tensor dimensions rather than stored as static buffers, enabling multi-resolution training without padding or fixed-shape assumptions.
Data augmentation and preprocessing run through stratum-hq. Horizontal flip augmentation was explicitly excluded: for a model conditioned on DWPose keypoints, flipping pixel data without remapping symmetric landmark indices (left eye ↔ right eye, left shoulder ↔ right shoulder) corrupts the cross-attention binding between spatial tokens and text tokens. The FFHQ dataset provides sufficient orientation diversity without flips.
The Ablation Design
We trained four arms for 5,000 steps each, all on the same physical quad-GPU Vast.ai node with GPU assignment pinned via CUDA_VISIBLE_DEVICES. Running every arm on the same hardware eliminates variance from GPU-to-GPU silicon differences — an often underappreciated confound in ablation studies that share results across separately provisioned machines.
| Arm | Optimizer | TREAD | Loss Formulation |
|---|---|---|---|
| A — Baseline | AdamW | Off | Standard flow-matching |
| B — TREAD+AdamW | AdamW | On | Standard flow-matching |
| C — TREAD+Muon | Muon | On | Standard flow-matching |
| D — Full Stack | Muon | On | Flow-matching + REPA |
TREAD (Token Routing for Efficient Architecture-agnostic Diffusion Training) probabilistically routes up to 50% of tokens around intermediate attention and feed-forward blocks. Tokens are extracted at an early layer and reinjected near the output, bypassing the bulk of the network’s compute. The theoretical promise is a direct reduction in FLOPs for those bypassed tokens, and because bypassed tokens still contribute to the loss, early layers receive a gradient signal from late-stage objectives — a form of pseudo-deep supervision.
Muon (Jordan & others, 2024) is a spectral optimizer that applies orthogonalized Nesterov momentum via a Newton-Schulz polynomial iteration, producing update matrices that converge to the nearest orthogonal matrix. Unlike AdamW’s per-parameter scalar moment estimation, Muon enforces a uniform update magnitude across each weight matrix. As a practical bonus, Muon’s single momentum buffer costs 4 bytes per parameter versus AdamW’s 8 (two buffers), reducing optimizer state memory by 50% — meaningful at this hardware budget.
REPA (Representation Alignment) (Yu et al., 2024) augments the flow-matching objective with an alignment penalty between the DiT’s intermediate hidden states and DINOv2’s semantic representations, forcing the generative student to internalize the teacher’s structure. Because this adds a second term to the loss with a different scale, Arm D’s raw loss values are not comparable to A, B, or C. LPIPS comparisons across all arms remain valid.
Results
Final Checkpoint (Step 5000)
| Arm | Recon LPIPS ↓ | Text LPIPS ↓ | Text Manip delta ↑ |
|---|---|---|---|
| A — Baseline | 0.9352 | 0.9593 | 0.466 |
| B — TREAD+AdamW | 1.0161 | 0.9396 | 0.373 |
| C — TREAD+Muon | 0.9463 | 0.9603 | 0.546 |
| D — Full Stack | 0.9267 | 0.9219 | 0.431 |
Recon LPIPS: reconstruction fidelity given full conditioning (identity + text), 25 samples. Text LPIPS: generation quality given text only, 20 samples. Text Manip delta: mean absolute LPIPS difference between generations for a caption and a single-attribute edit (e.g., “dark hair” → “light hair”) — a measure of how decisively the model responds to text.
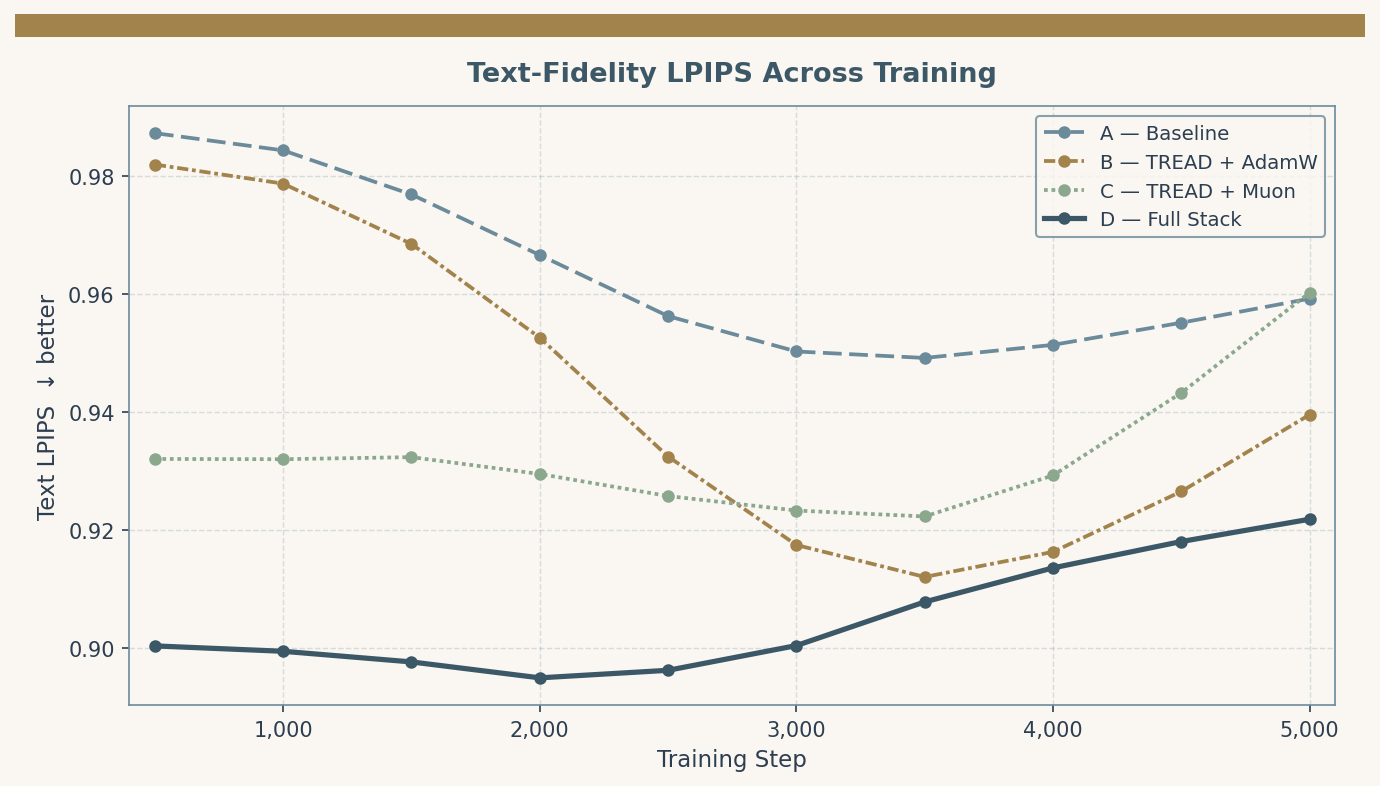
All TREAD arms (B, C, D) trained approximately 17% faster in wall-clock time: ~95h versus ~112h for the baseline. At equivalent step budgets this is a direct reduction in future experiment cost.
What We Did Not Expect: AdamW+TREAD Instability
Arm B’s result requires a post-mortem. It achieved its best reconstruction at step 3000 (Recon LPIPS 0.906 — briefly the best of any arm) and then collapsed monotonically to 1.016 by step 5000, a value exceeding 1.0, meaning the model performs worse than a trivial baseline on reconstruction at its final checkpoint.
The collapse is not sudden. It begins around step 3500 and degrades progressively — which is why we did not catch it early. A prior independent run showed the same pattern, confirming this is reproducible behavior rather than a stochastic outlier.
The mechanism is a mathematical incompatibility between AdamW’s adaptive moment estimation and TREAD’s dynamic spatial sparsity. TREAD routes tokens around intermediate blocks, so those blocks receive sparse, irregular gradient signals over thousands of iterations. AdamW interprets near-zero gradients as low-variance parameters and decays their second-moment estimates accordingly. This inflates the adaptive learning rate for those “starved” weights. When a high-frequency token is eventually routed through a starved block, the resulting gradient is multiplied by the inflated rate and produces a divergent update that shatters the block’s representations. The failure accumulates gradually and then becomes catastrophic.
This is not a deficiency in TREAD itself. It is a fundamental incompatibility between per-parameter scalar moment estimation and dynamic spatial routing. Do not use TREAD with AdamW for long runs.
Muon as the Fix
Arm C demonstrates the resolution. Muon’s orthogonalized updates enforce a fixed spectral norm across the entire weight matrix, not per-parameter scaling. There are no “starved” parameters — every weight receives a geometrically uniform step. The TREAD-induced sparsity pattern becomes irrelevant because the optimizer is not accumulating per-parameter learning rate history in a way that can diverge.
The result: Arm C’s Recon LPIPS (0.946) is 0.070 points better than Arm B’s final collapse, within 0.011 of the stable baseline (Arm A), with the full 17% throughput gain intact. And its Text Manipulation delta (0.546) is the highest of any arm — Muon’s isotropic updates appear to promote stronger, more decisive binding between text token activations and output features. For a model where the primary use case is text-driven portrait control, this matters.
Full Stack as the Production Target
Arm D (TREAD + Muon + REPA) achieves the best metrics across both dimensions: Recon LPIPS 0.927, Text LPIPS 0.922. The REPA loss accelerates early semantic acquisition — Arm D’s Text LPIPS broke below 0.90 by step 500, while other arms reached comparable values much later. Muon’s stability allowed the model to reach final convergence without the instabilities that would accompany the modified dual-objective loss under AdamW.
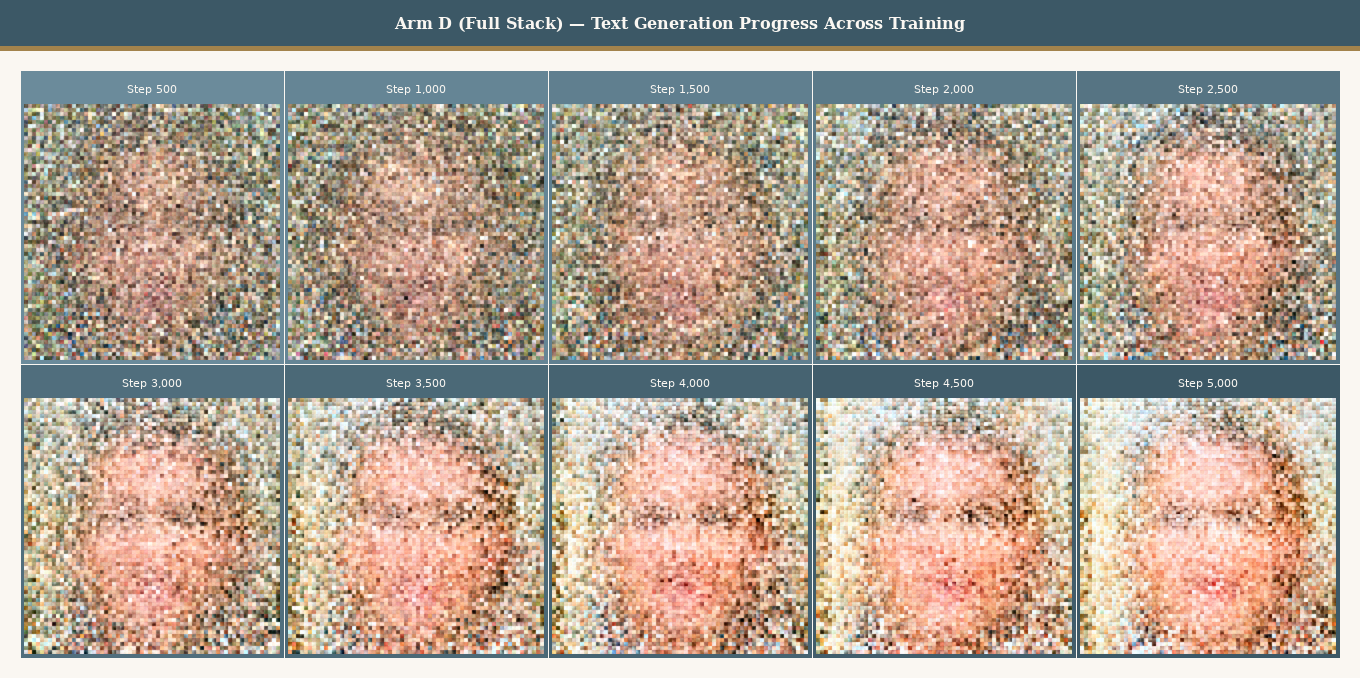
The following collage shows text-only outputs from all four arms at their final checkpoint (step 5000), using the same evaluation prompt. Arm D’s output consistently shows stronger structural coherence and finer detail.

The Traps Ahead
Completing the study also clarified several failure modes we need to address for production-scale training.
REPA termination. DINOv3 is a discriminative model operating in a lower-dimensional embedding space optimized for classification and dense feature matching. It discards high-frequency textural variance — pores, hair strands, skin texture — that photorealism requires. In the burn-in phase, REPA’s alignment penalty is genuinely helpful: it pulls the DiT out of its initial chaotic state. Beyond that, the teacher’s embeddings become a constraint, penalizing the generator for synthesizing details that don’t exist in the teacher’s feature maps. The HASTE framework describes this as the “works until it doesn’t” trap. For production runs, the REPA alignment weight should be decayed to zero by approximately step 1000–1500 (the first 20–30% of a 5000-step run), then let the model converge on unconstrained flow-matching alone. Our current 5000-step study ran REPA to completion — the metrics are still the best of any arm, but we likely left quality on the table.
Pixel scaling. When processing RGB data directly without a VAE bottleneck, images must be scaled correctly into the [−1, 1] range expected by the diffusion process. Currently, the dataloader yields [0, 1] RGB pixels, which slightly biases the flow-matching objective. Correcting the pixel normalization pipeline is a prerequisite for reliable convergence at scale.
Spatial evaluation. LPIPS measures perceptual texture similarity and broad structural alignment. It cannot verify whether the generated pose matches the DWPose conditioning input. A model can generate a photorealistic face (excellent LPIPS) while completely ignoring the jaw angle or shoulder position specified by the spatial condition. The next iteration needs MPJPE (Mean Per Joint Position Error) in the validation loop — specifically PA-MPJPE (Procrustes-Aligned MPJPE), which isolates structural accuracy from rotational and scale variance — to prove that the DiT’s cross-attention mechanisms actually bind visual output to spatial conditions.
What’s Next
The ablation clears the path for the next phase of prx-tg development. The production training configuration is Full Stack (Arm D) with REPA loss decay implemented from the start. The immediate engineering priorities are:
- Implement REPA warmdown scheduling — decay the alignment weight to zero by step ~1250 for a 5000-step run, or proportionally for longer budgets.
- Pixel normalization pipeline — ensure RGB tensors are properly centered at zero
[−1, 1]before DiT input. - MPJPE/PA-MPJPE validation — instrument the validation loop with a second-stage pose estimator to measure spatial controllability quantitatively.
- Longer runs — the 5000-step study was designed to isolate optimizer dynamics under controlled conditions. Production-quality generation at 1024×1024 will require substantially more steps. The 17% throughput gain from TREAD directly compounds the value of every future training hour.
The study confirms that the engineering hypothesis holds: state-of-the-art multi-modal generation at 1024×1024 is trainable on a single consumer GPU. It does not require a cluster — it requires careful memory engineering, the right optimizer for the architecture, and disciplined ablation to understand what fails and why.
Code and Data
The full ablation write-up, per-checkpoint metrics, and arm configurations are in the repository:
- prx-tg: github.com/timlawrenz/prx-tg — model, training code, ablation docs
- stratum-hq: github.com/timlawrenz/stratum-hq — data ingestion, preprocessing, augmentation pipeline
- Ratiocinator: github.com/timlawrenz/ratiocinator — the autonomous experiment runner that provisioned and monitored the ablation
References
- Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers. Proceedings of the IEEE/CVF International Conference on Computer Vision.
- Jordan, K., & others. (2024). Muon: An Optimizer for Hidden Layers in Neural Networks. ArXiv Preprint.
- Yu, S., Jin, S., Lee, J., Kim, J., & Shin, J. (2024). Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. ArXiv Preprint ArXiv:2410.06940.